
BOOTSTRAPPING NON-PARALLEL VOICE CONVERSION FROM SPEAKER-ADAPTIVE
TEXT-TO-SPEECH
Hieu-Thi Luong
1,2
, Junichi Yamagishi
1,2,3
1
SOKENDAI (The Graduate University for Advanced Studies), Kanagawa, Japan
2
National Institute of Informatics, Tokyo, Japan
3
The University of Edinburgh, Edinburgh, UK
ABSTRACT
Voice conversion (VC) and text-to-speech (TTS) are two tasks
that share a similar objective, generating speech with a target
voice. However, they are usually developed independently
under vastly different frameworks. In this paper, we propose
a methodology to bootstrap a VC system from a pretrained
speaker-adaptive TTS model and unify the techniques as well
as the interpretations of these two tasks. Moreover by offload-
ing the heavy data demand to the training stage of the TTS
model, our VC system can be built using a small amount of
target speaker speech data. It also opens up the possibility of
using speech in a foreign unseen language to build the system.
Our subjective evaluations show that the proposed framework
is able to not only achieve competitive performance in the
standard intra-language scenario but also adapt and convert
using speech utterances in an unseen language.
Index Terms— voice conversion, cross-lingual, speaker
adaptation, transfer learning, text-to-speech
1. INTRODUCTION
The voice conversion (VC) system is used to convert speech
of a certain speaker to speech of a desired target while retain-
ing the linguistic content [1]. VC and text-to-speech (TTS)
systems are two different systems functioning under different
scenarios, but they share a common goal: generating speech
with a target voice. If we define the TTS system as a syn-
thesis system generating speech using linguistic instructions
(in an abstract sense) obtained from written text [2], then the
VC system can be defined as a synthesis system generating
speech using linguistic instructions extracted from a reference
utterance. This similarity in objective but difference in oper-
ation context makes VC and TTS complement each other and
have their unique role in a spoken dialogue system. More
specifically, as text input is easy to create and modify, TTS is
capable of generating a large amount of speech automatically
and cheaply. However it is difficult to generate speech when
the desired linguistic instructions cannot be represented in the
This work was partially supported by a JST CREST Grant (JP-
MJCR18A6, VoicePersonae project), Japan, and MEXT KAKENHI Grants
(16H06302, 17H04687, 18H04120, 18H04112, 18KT0051), Japan.
expected written form (e.g. when text is written in foreign
languages). On the other hand, speech used as a reference
input for VC is more time-consuming and expensive to pro-
duce, but the system can be straightforwardly extended to an
unseen language.
A VC system is usually classified as parallel or non-
parallel depending on the nature of the data available for
development. The parallel VC system is developed using
a parallel corpus containing pairs of utterance spoken by a
deterministic source and target speakers. The parallel speech
utterances of source and target are aligned using dynamic
time warping (DTW) to create the training set. By using this
training set, a mapping function is formulated to transform
the acoustic features of one speaker to another [3]. Many
methods have been proposed to model this transformation
for parallel VC systems [1, 4, 5]. Parallel VC is developed
with just data of source and target speakers which is one
of its advantages. Acquisition of parallel speech data re-
quires a lot more planning and preparation than acquisition
of non-parallel speech, which in turn makes the former more
expensive to develop, especially when we want a VC system
with the voice of a particular speaker. Therefore, many ap-
proaches have been proposed to develop VC systems using
a non-parallel corpus [6, 7]. For the conventional Gaussian
mixture model (GMM) approach, non-parallel VC can be
adapted from a pretrained parallel VC in the model space
using the maximum a posterior (MAP) method [7, 8] or as
interpolation between multiple parallel models [9]. For recent
neural network approaches, a non-parallel VC can be trained
by directly using an intermediate linguistic representation
extracted from an automatic speech recognition (ASR) model
[10, 11] or by indirectly encouraging the network to disen-
tangle linguistic information from the speaker characteristics
using methods like variational autoencoder (VAE) [12], gen-
erative adversarial networks (GAN) [13, 14] or some other
techniques [15]. For both parallel and non-parallel VC, the
systems usually change the voice but are unable to change
the duration of the utterance. Many recent researches fo-
cused on converting speaking rate along with voices by using
sequence-to-sequence models [11, 16, 17, 18], as speaking
rate is also a speaker characteristic.
Recently Luong et al. proposed a speaker-adaptive TTS
arXiv:1909.06532v1 [eess.AS] 14 Sep 2019

Dec
LEnc
spkcode
μ σ
AEnc
ε
μ σ
x
y
y
KLD
MAE
loss
Fig. 1. Training the initial speaker-adaptive TTS model.
model that could perform speaker adaptation with untran-
scribed speech using backpropagation algorithm [19]. We
find that the proposed system can potentially be used for
developing non-parallel VC as well. In this paper, we in-
troduce a framework for creating a VC system using the
untranscribed speech of a target speaker by bootstrapping
from the speaker-adaptive TTS model proposed by Luong et
al. [19]. Furthermore, we investigate the performance of our
framework when it adapts and convert using speech utter-
ances of an unseen language. The rest of paper is organized
as follows. Section 2 describes our framework, Section 3
introduces different scenarios in which a VC can operate in
an unseen language and their practical applications, Section 4
describes the experiment setup, Section 5 presents subjective
results, and Section 6 concludes our findings.
2. BOOTSTRAPPING VOICE CONVERSION FROM
SPEAKER-ADAPTIVE TTS
2.1. Multimodal architecture for speaker-adaptive TTS
We first summarize the speaker-adaptive TTS proposed in
[19]. A conventional TTS model is essentially a function that
transforms linguistic features x, extracted from a given text,
to the acoustic features y, which could be used to synthesize
speech waveform. A neural TTS model is a TTS model that
uses neural networks as the approximation function for the x
to y transformation. Neural networks are trained with back-
propagation algorithm and can also be adapted to a new un-
seen domain with backpropagation when the adaptation data
is labeled. In the context of TTS, an acoustic model can
easily be adapted to voices of unseen speakers if the adap-
tation data is transcribed speech but it is not as straightfor-
ward when the adaptation is untranscribed. Many techniques
Dec
AEnc
μ
y
y
MAE
Fig. 2. Transferring to VC and adapting to the target speaker.
have been proposed to perform adaptation with untranscribed
speech by avoiding backpropagation and extracting a certain
speaker representation from an external system instead [20,
21]. However, this forward-based approach limited the per-
formance of the adaptation process [19].
Luong et al. [19] proposed backpropagation-based adap-
tation method using untranscribed speech by introducing a
latent variable z, namely latent linguistic embedding (LLE),
which presumably contains no information about the speak-
ers. The conventional acoustic model then splits into a
speaker-dependent (SD) acoustic decoder Dec and a speaker-
independent (SI) linguistic encoder LEnc. The acoustic
decoder is defined by its SI parameter θ
core
and SD parameter
θ
spk,(k)
, one for each k-th speaker in the training set while the
linguistic encoder is defined by its SI parameter φ
L
. The TTS
model can be described as follows:
z
L
∼ LEnc(x; φ
L
) = p(z|x) (1)
˜y
L
= Dec(z
L
; θ
core
, θ
spk,(k)
) (2)
With this new factorized model, if we want to adapt the acous-
tic decoder to unseen speakers using speech, we train an aux-
iliary acoustic encoder AEnc (defined by its SI parameter
φ
A
) to use as a substitute for the linguistic encoder:
z
A
∼ AEnc(y; φ
A
) = q(z|y) (3)
˜y
A
= Dec(z
A
; θ
core
, θ
spk,(k)
) (4)
The acoustic encoder is only used to perform the unsuper-
vised speaker adaptation in [19]; however the network cre-
ated by stacking the acoustic encoder and acoustic decoder is
essentially a speech-to-speech stack that potentially could be
used as a VC system. This is the motivation for us to develop
a VC framework based on this model.
2.2. Latent Linguistic Embedding for many-to-one voice
conversion
By using the speaker-adaptive TTS model described above,
we propose a three-step framework to develop a VC system
for a target speaker:
1) train the initial TTS model: The first step is to train
the TTS model, it is identical to the training mode defined in
Section IV-B in [19]. The data required for this step is a multi-
speaker transcribed speech corpus. In this step, we need to
jointly train all modules using a deterministic loss function:
loss
train
= loss
main
+ β loss
tie
(5)
loss
main
is the distortion between output of the TTS stack
and the natural acoustic features, and loss
tie
is the KL diver-
gence (KLD) between the output of the linguistic encoder and
output of the acoustic encoder. The setup is almost the same
as described in [19]. One small difference is that we use the
mean absolute error (MAE) as the distortion function instead
of the mean square error as shown in Fig. 1. In this step, the
acoustic encoder is trained to transform acoustic features to
the linguistic representation LLE while the acoustic decoder
is trained to become a good initial model for speaker adapta-
tion.
2) transfer to VC and adapt to the target: For build-
ing a VC system we only need the acoustic encoder and the
acoustic decoder trained previously; the linguistic encoder is
discarded as it is no longer needed. The acoustic encoder and
decoder make a complete speech-to-speech network. To have
a VC system with a particular voice we adapt the acoustic
decoder using the available speech data of the target. This
is identical to the unsupervised adaptation mode described
in Section IV-B in [19]. More specifically, we removed all
SD parameters θ
spk,(k)
and then fine-tuned remaining param-
eter θ
core,(r)
to the r-th target speaker by minimizing the loss
function:
loss
adapt
= L
MAE
(˜y
A
, y) (6)
Slightly different to [19], we removed the standard deviation
σ from the acoustic encoder as illustrated in Fig. 2. Simply
speaking instead of sampling z
A
from a distribution (Equa-
tion 3), z
A
will always take the mean value instead. We found
this change slightly improves the performance of the adapted
model in the converting step.
3) converting speech of arbitrary source speakers: The
adapted VC system then could be used to convert speech of
arbitrary source speakers to the target. Our system does not
need to train on or adapt to the speech data of source speakers,
although doing so might help the performance.
2.3. Related works
While the original VC is narrowly defined as a function that
directly maps acoustic units of a source to a target speaker
[3, 22], recent VC systems have usually been modeled with
an intermediate linguistic representation, either explicitly [10]
or implicitly [23] due to the rapid development of representa-
tion learning and disentanglement ability of neural networks.
This approach has further reduced the theoretical difference
between VC and TTS. Motivated by the same observation,
Mingyang Zhang et al. [24] proposed a method to jointly train
a TTS and a parallel VC system using a shared sequence-to-
sequence model. The proposed framework improves the sta-
bility of the generated speech but does not add any benefits in
term of data efficiency, as parallel speech data of the source
and target speakers is still a requirement. Recently, Jing-Xuan
Zhang et al. [18] have introduced a non-parallel sequence-to-
sequence voice conversion system that has a procedure that
is similar to our: the initial model is trained with a TTS-like
network to help disentangle linguistic representation and the
model then adapted to the source and target speakers. How-
ever, the adaptation step of the framework proposed in [18] re-
quires both source and target speaker speech as well as their
transcripts, which increases the data demand for building a
VC system with a particular voice.
Despite being different in motivation and procedure, our
framework has the same data efficiency as the models using
phonetic posteriorgrams (PPG) proposed by Sun et al. [10].
The LLEs in our setup play a similar role to the PPGs, but are
very different in terms of characteristics. While PPGs are the
direct output of an ASR network with an explicit interpreta-
tion, LLEs are latent variables and guided by a TTS network.
The efficiency in terms of data usage is not only lowering the
requirement for building a VC system but also opening up the
possibility of solving other interesting tasks. Creating and us-
ing the VC system with a low-resource unseen language is
one example [25].
3. USING VOICE CONVERSION SYSTEM IN AN
UNSEEN LANGUAGE
The proposed three-step framework have an interesting char-
acteristic which is the asymmetric nature in terms of data re-
quirements for each step. While the TTS training step re-
quires a transcribed multi-speaker corpus, the adaptation step
only requires a small amount of untranscribed speech from
the target speaker. Moreover the model does not need to train
on data of source speakers and hypothetically can convert ut-
terances of arbitrary speakers out of the box. We could take
advantage of these characteristics to build VC systems for
low-resource languages. For our experiments, we define the
abundant language as language with transcribed speech cor-
pus and used to train the initial TTS model (seen); in our case
it is English (E). The low-resource language is a language
whose data does not include transcripts and is not used in the
TTS step (unseen); in our case it is Japanese (J). We first de-
fine multiple scenarios in which our framework can interact
with an unseen language. These scenarios are dictated by the
language used in the adaptation and conversion steps:
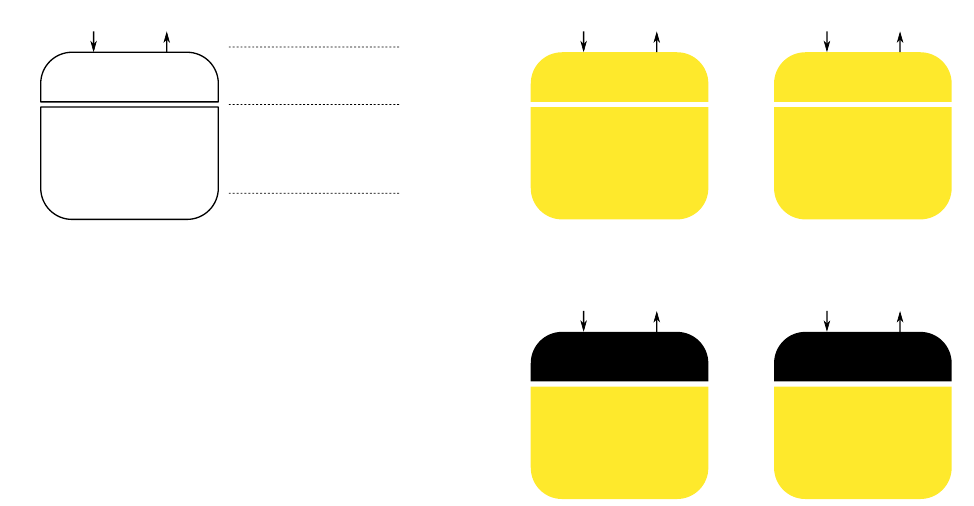
Pretrain
Adaptation
Conversion
Speech and transcript data of
multiple speakers
Speech data of the
target speaker
An utterance of a
source speaker
Data requirements
Fig. 3. The asymmetric nature of data requirements for each
step of the proposed framework.
(a) EE-E: We adapt the pretrained English model to an
English speaker and using it to convert English utterances.
Generally speaking the entire framework from start to finish
operates within a single language. This is the typical intra-
language scenario of a voice conversion system.
(b) EE-J: We adapt the pretrained English model to
an English speaker but use it to convert Japanese utterances.
Generally speaking, the VC system is used to generate speech
of linguistic instructions that have not been seen. The ability
to generate speech for content that is difficult to represent in
the expected written form (a foreign language in this case) is
one advantage of VC over TTS. This scenario is referred as
cross-language voice conversion [26, 27].
(c) EJ-E: We adapt the pretrained English model to a
Japanese speaker and use it to convert English utterances. In
this scenario we want to build a VC system in the abundant
language; however, the speech data of the target speaker is
only available in a low-resource unseen language. This is
sometime referred to as cross-lingual voice conversion [28,
29], however we call it cross-language speaker adaption to
distinguish it from EE-J. Unlike other scenarios involving the
unseen language, cross-language speaker adaptation is rele-
vant for both VC [28] and TTS [30, 25]. Even though it is
not evaluated in this paper, this scenario is also the unsuper-
vised cross-language speaker adaptation scenario of the TTS
system proposed in [19].
(d) EJ-J: We adapt the pretrained English model to a
Japanese speaker and use it to convert Japanese utterances.
In this scenario we essentially bootstrap a VC system for a
low-resource language from a pretrained model of an abun-
dant one. The written form of the target language is not used
in the training, the adaptation or the conversion stages. This
scenario is sometime referred as text-to-speech without text,
which is the main topic of the Zero Resource Speech Chal-
lenge 2019 [31]. Even though our scenario has the same
objective as the challenge, the approach is a little different.
The participant of the challenge are encouraged to develop
intra-language unsupervised unit discovery methods, which
are more difficult [32, 33, 34]. Our framework is bootstrapped
from an abundant language, which is a more practical ap-
proach [35, 36].
English
English
English English
English
English
⽇本語 ⽇本語
(a) EE-E (b) EE-J
English
⽇本語
English English
English
⽇本語
⽇本語 ⽇本語
(c) EJ-E (d) EJ-J
Fig. 4. Different scenarios of using a non-parallel voice con-
version system with unseen language. In this paper, English
plays the role of the abundant language (seen) while Japanese
plays the role of the low-resource language (unseen).
4. EXPERIMENT
4.1. Dataset
We used 25.6 hours of transcribed speech from 72 English
speakers to train the initial speaker-adaptive TTS model and
the initial SI WaveNet vocoder. The data is a subset of the
VCTK speech corpus [37]. To validate the proposed method,
we reenact the SPOKE task of the Voice Conversion Chal-
lenge 2018 (VCC2018) [38]. We build the VC system for 4
target speakers (2 males and 2 females) using 81 utterances
per person. We then evaluate the SPOKE task using the
speech of 4 source speakers (2 males and 2 females); each
speaker contribute 35 utterances. Even though the task pro-
vided training data for the source speakers, we did not use
the training data in our experiments as our model can convert
speech of an arbitrary source speaker.
To test the performance of the proposed system in the con-
text of unseen language as described in Section 3, we use 2
in-house bilingual speakers (1 male and 1 female) as the new
targets speakers. These two target speakers can speaker En-
glish and Japanese at almost native level. 400 utterances per
speaker per language are used as training data; 10 more ut-
terances are used for validation. For evaluation, we reuse
2 source speakers (1 male and 1 female) from VCC2018 as
the English source speakers and add 2 native Japanese speak-
ers (1 male and 1 female) as the Japanese source speakers.
1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0
Quality
1.0
1.5
2.0
2.5
3.0
3.5
4.0
Similarity
N10
OUR
B01
Fig. 5. Subjective results for the SPOKE task of the Voice
Conversion Challenge 2018. The lines indicate 95% confi-
dence interval with all results are statistically significant.
Table 1. Detailed subjective results for SPOKE task.
(a) Quality
F-F F-M M-F M-M ALL
N10 3.91 3.96 3.85 3.93 3.91
B01 3.10 2.12 1.84 2.49 2.39
OUR 2.72 2.77 2.41 2.68 2.65
(b) Similarity
F-F F-M M-F M-M All
N10 3.18 3.55 3.14 3.48 3.33
B01 2.74 2.87 2.21 2.04 2.47
OUR 2.92 3.13 2.70 3.26 3.00
Each source speaker contributes 35 utterances for evaluation.
While Japanese plays the role of the low-resource in our ex-
periments, to provide a good reference, we train an additional
system in which Japanese is the abundant language and then
use it as the upper bound. This intra-lingual VC system for
Japanese, namely JJ-J, is pretrained on 44.9 hours of tran-
scribed speech of 235 native speakers and then adapted to the
Japanese training speech of the two bilingual target.
4.2. Model configuration
Our configuration imitates the setup described in [19] as
closely as possible. The linguistic feature is a 367-dimensional
vector contained various information that is deemed to be use-
ful for English speech synthesis. The acoustic feature is the
80-dimensional mel-spectrogram. One difference compared
with [19] is that all speech data is resampled to 22050 Hz
(which is the sampling rate of the VCC2018 dataset) before it
is used to extract acoustic features. WaveNet vocoder is also
trained on the 22050 Hz waveform that has been quantized
using 10-bit u-law.
The neural network used for the speaker-adaptive acous-
tic model has the same structure as in [19] with the size of
NA-E EE-E EJ-E
(a) Quality
1.0
1.5
2.0
2.5
3.0
3.5
4.0
4.5
5.0
NA-E EE-E EJ-E
(a) Similarity
1.0
1.5
2.0
2.5
3.0
3.5
4.0
Fig. 6. Subjective results for cross-language speaker adapta-
tion task. All results are statistically significant.
the LLE set to 64. Speaker bias is placed at layers B5, B6,
B7, and B8 (Fig. 1 in [19]) in the form of a one-hot-vector
to represent speakers in the training set. The initial multi-
modal architecture is trained using the loss function defined
in Equation 5 with β set to 0.25. The SI WaveNet vocoder
contained 40 dilated causal layers and it is conditioned on a
natural mel-spectrogram. The WaveNet vocoder is fine-tuned
for each target speaker using their respective available train-
ing speech data.
5. EVALUATION AND DISCUSSION
5.1. Voice conversion challenge 2018 SPOKE task
We follow the guidelines of VCC2018 and build systems
for the 4 target speakers of the SPOKE task and converting
evaluation utterances of the 4 source speakers. We compare
our system (OUR) with B01 [39], which is the baseline of
VCC2018, and N10 [40], which is the best system based on
the subjective test. Instead of reproducing the experiments
for B01 and N10, we use the utterances submitted by the
participants to ensure the highest quality. We conduct the
listening test to judge the quality and similarity of utterances
generated by the OUR, B01 and N10 systems. A total of
28 native English speakers participated in our test, most of
them did approximately 10 sessions. Each session is prepared
to contain generated utterances of every target speaker from
every system. In summary, each system is judged 1088 times
for quality and another 1088 times for similarity. In the qual-
ity question, the participant is asked to judge the quality of
the represented speech sample using a 5-point scale mean-
opinion score. In the similarity question, the participant is
asked to judge the similarity between the utterance generated
by one VC system and a natural utterance spoken by the
target speaker in a 4-point scale. The setup is the same as in
VCC2018 [38].
The general results can be seen in Fig. 5. While it is not as
good as the best system N10, our system is slightly better than
the baseline B01 in terms of quality and significantly better in
terms of speaker similarity. One should note that B01 is a
strong baseline, it is ranked 3rd in quality and 6th in speaker

1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0
EE-J
EJ-J
JJ-J
NA-J
Fig. 7. Quality evaluations for low-resource language voice
conversion. All results are statistical significant.
similarity measurements at the VCC2018 [38]. This validated
our framework for VC. More detailed results can be found in
Table 1, which shows consistent performance of our system
across same-gender and cross-gender pairs.
5.2. Cross-language speaker adaptation
Next, we evaluate our system in the scenario of cross-
language speaker adaptation (EJ-E). For this task we develop
a system using the speech data of the bilingual target speak-
ers. We compare EJ-E with EE-E, which is the standard
intra-language of English, and a reference system NA-E,
which is of hold-out natural English utterances.
The native English speakers that participated in the sur-
vey for previous task are asked to evaluate the cross-language
speaker adaptation task as well. In summary, each scenario
is judged 544 times for quality and another 544 times for
similarity. The quality and similarity results are illustrated
in Fig. 6 and are statistically significant between all scenar-
ios. The cross-language speaker adaptation EJ-E is generally
worse than EE-E as one would expect.
5.3. Voice conversion for low-resource language
Finally, we test the performance of our system when using
it to convert speech of low-resource language. This consists
of the EE-J and EJ-J scenarios. We use JJ-J, the abundant
language scenario of Japanese, as the upper-bound and NA-J,
the hold-out natural Japanese utterances, as the reference. We
prepare a similar listening test to that of previous tasks. A
total 148 native Japanese participated in our test; no partici-
pant is allowed to do more than 10 sessions. Each session is
prepared to contain all source and target pairs. In summary,
each scenario is judged 2800 times for quality and another
2800 times for similarity except the reference natural speech,
which is only judged 1400 times for each measurement.
The result of the quality test is illustrated in Fig. 7. Our
standard Japanese system JJ-J achieved a relatively better
score than the English counterpart EE-E, although technically
they should not be compared directly. The cross-language
converting scenarios, EJ-J and EE-J, are a lot worse than the
standard scenario JJ-J; as expected EJ-J has slightly better
score than EE-J. The result for the similarity test is illustrated
in Fig. 8. For the four systems that convert Japanese speech,
their similarity result trend is the same as their quality result
0 20 40 60 80 100
NA-E
EE-E
EE-J
EJ-J
JJ-J
NA-J
same (sure)
same (not sure)
different (not sure)
different (sure)
Fig. 8. Similarity evaluations for low-resource language voice
conversion.
trend. For the similarity test, we also included two extra sys-
tems that produce English speech, EE-E and NA-E. In these
two cases the listener would listen to an English utterance
contributed by EE-E or NA-E and a natural Japanese utter-
ance of the same speaker (as the target speakers are bilingual)
and judge their similarity. Interestingly the similarity result of
NA-E is a lot worse than that of NA-J even though they both
contain natural speech spoken by the same speaker in real life.
This suggests that utterances spoken by the same speaker in
different languages might not have consistent characteristic.
Or problem might be that is it difficult for listeners to evalu-
ate speaker similarity in cross-language scenario, especially
when they are not fluent in both.
Even though the performance in the unseen language sce-
narios is not as good as the standard scenario, the subjective
results have shown the ability of using our system for inter-
language tasks and establishing a preliminary result as well as
a solid baseline for future improvements
1
.
6. CONCLUSION
In this paper, we have presented a methodology to bootstrap
a VC system from a pretrained speaker-adaptive TTS model.
By transferring knowledge learned previously by the TTS
model, we were able to significantly lower the data require-
ments for building the VC system. This in turn allows the
system to operate in a low-resource unseen language. The
subjective results show that our VC system achieves competi-
tive performance compared with existing methods. Moreover,
it can also be used for cross-language voice conversion and
cross-language speaker adaptation. While the performance
in these unseen language scenarios are not as good, all ex-
periments in this work are conducted under the assumption
of minimal available resources. Our future work includes
taking advantage of the available additional resources such
as a multi-lingual corpus [28, 41] to further improve the
robustness of the VC system.
1
Speech samples are available at https://nii-yamagishilab.
github.io/sample-vc-bootstrapping-tts/
7. REFERENCES
[1] Tomoki Toda, Alan W Black, and Keiichi Tokuda,
“Voice conversion based on maximum-likelihood esti-
mation of spectral parameter trajectory,” IEEE Trans.
Audio, Speech, Language Process., vol. 15, no. 8, pp.
2222–2235, 2007.
[2] Paul Taylor, Text-to-speech synthesis, Cambridge uni-
versity press, 2009.
[3] Masanobu Abe, Satoshi Nakamura, Kiyohiro Shikano,
and Hisao Kuwabara, “Voice conversion through vector
quantization,” J. Acoust. Soc. Jpn. (E), vol. 11, no. 2,
pp. 71–76, 1990.
[4] Ryoichi Takashima, Tetsuya Takiguchi, and Yasuo
Ariki, “Exemplar-based voice conversion using sparse
representation in noisy environments,” IEICE Transac-
tions on Fundamentals of Electronics, Communications
and Computer Sciences, vol. 96, no. 10, pp. 1946–1953,
2013.
[5] Ling-Hui Chen, Zhen-Hua Ling, Li-Juan Liu, and Li-
Rong Dai, “Voice conversion using deep neural net-
works with layer-wise generative training,” IEEE/ACM
Transactions on Audio, Speech and Language Process-
ing (TASLP), vol. 22, no. 12, pp. 1859–1872, 2014.
[6] Daniel Erro, Asunci
´
on Moreno, and Antonio Bonafonte,
“INCA algorithm for training voice conversion systems
from nonparallel corpora,” IEEE Trans. Audio, Speech,
Language Process., vol. 18, no. 5, pp. 944–953, 2009.
[7] Yining Chen, Min Chu, Eric Chang, Jia Liu, and Run-
sheng Liu, “Voice conversion with smoothed gmm and
map adaptation,” in Proc. EUROSPEECH, 2003, pp.
2413–2416.
[8] Chung-Han Lee and Chung-Hsien Wu, “Map-based
adaptation for speech conversion using adaptation data
selection and non-parallel training,” in Proc. INTER-
SPEECH, 2006, pp. 2254–2257.
[9] Tomoki Toda, Yamato Ohtani, and Kiyohiro Shikano,
“Eigenvoice conversion based on gaussian mixture
model,” in Proc. INTERSPEECH, 2006, pp. 2446–2449.
[10] Lifa Sun, Kun Li, Hao Wang, Shiyin Kang, and He-
len Meng, “Phonetic posteriorgrams for many-to-one
voice conversion without parallel data training,” in
2016 IEEE International Conference on Multimedia and
Expo (ICME). IEEE, 2016, pp. 1–6.
[11] Hiroyuki Miyoshi, Yuki Saito, Shinnosuke Takamichi,
and Hiroshi Saruwatari, “Voice conversion us-
ing sequence-to-sequence learning of context posterior
probabilities,” Proc. INTERSPEECH, pp. 1268–1272,
2017.
[12] Chin-Cheng Hsu, Hsin-Te Hwang, Yi-Chiao Wu,
Yu Tsao, and Hsin-Min Wang, “Voice conversion from
non-parallel corpora using variational auto-encoder,” in
Proc. APSIPA. IEEE, 2016, pp. 1–6.
[13] Takuhiro Kaneko and Hirokazu Kameoka, “Parallel-
data-free voice conversion using cycle-consistent ad-
versarial networks,” arXiv preprint arXiv:1711.11293,
2017.
[14] Fuming Fang, Junichi Yamagishi, Isao Echizen, and
Jaime Lorenzo-Trueba, “High-quality nonparallel voice
conversion based on cycle-consistent adversarial net-
work,” in 2018 IEEE International Conference on
Acoustics, Speech and Signal Processing (ICASSP).
IEEE, 2018, pp. 5279–5283.
[15] Andros Tjandra, Berrak Sisman, Mingyang Zhang,
Sakriani Sakti, Haizhou Li, and Satoshi Nakamura,
“Vqvae unsupervised unit discovery and multi-scale
code2spec inverter for zerospeech challenge 2019,”
arXiv preprint arXiv:1905.11449, 2019.
[16] Cheng-chieh Yeh, Po-chun Hsu, Ju-chieh Chou, Hung-
yi Lee, and Lin-shan Lee, “Rhythm-flexible voice
conversion without parallel data using cycle-gan over
phoneme posteriorgram sequences,” in Proc. SLT, 2018,
pp. 274–281.
[17] Kou Tanaka, Hirokazu Kameoka, Takuhiro Kaneko, and
Nobukatsu Hojo, “Atts2s-vc: Sequence-to-sequence
voice conversion with attention and context preservation
mechanisms,” in Proc. ICASSP, 2019, pp. 6805–6809.
[18] Jing-Xuan Zhang, Zhen-Hua Ling, and Li-Rong Dai,
“Non-parallel sequence-to-sequence voice conversion
with disentangled linguistic and speaker representa-
tions,” arXiv preprint arXiv:1906.10508, 2019.
[19] Hieu-Thi Luong and Junichi Yamagishi, “A unified
speaker adaptation method for speech synthesis using
transcribed and untranscribed speech with backpropa-
gation,” arXiv preprint arXiv:1906.07414, 2019.
[20] Ye Jia, Yu Zhang, Ron J Weiss, Quan Wang, Jonathan
Shen, Fei Ren, Zhifeng Chen, Patrick Nguyen, Ruom-
ing Pang, Ignacio Lopez Moreno, and Yonghui Wu,
“Transfer learning from speaker verification to mul-
tispeaker text-to-speech synthesis,” arXiv preprint
arXiv:1806.04558, 2018.
[21] Eliya Nachmani, Adam Polyak, Yaniv Taigman, and
Lior Wolf, “Fitting new speakers based on a short un-
transcribed sample,” arXiv preprint arXiv:1802.06984,
2018.
[22] Yannis Stylianou, Olivier Capp
´
e, and Eric Moulines,
“Continuous probabilistic transform for voice conver-
sion,” IEEE Transactions on speech and audio process-
ing, vol. 6, no. 2, pp. 131–142, 1998.
[23] Hirokazu Kameoka, Takuhiro Kaneko, Kou Tanaka, and
Nobukatsu Hojo, “Acvae-vc: Non-parallel many-to-
many voice conversion with auxiliary classifier varia-
tional autoencoder,” arXiv preprint arXiv:1808.05092,
2018.
[24] Mingyang Zhang, Xin Wang, Fuming Fang, Haizhou
Li, and Junichi Yamagishi, “Joint training frame-
work for text-to-speech and voice conversion using
multi-source tacotron and wavenet,” arXiv preprint
arXiv:1903.12389, 2019.
[25] Lifa Sun, Hao Wang, Shiyin Kang, Kun Li, and Helen M
Meng, “Personalized, cross-lingual tts using phonetic
posteriorgrams.,” in Proc. INTERSPEECH, 2016, pp.
322–326.
[26] Masanobu Abe, Kiyohiro Shikano, and Hisao
Kuwabara, “Statistical analysis of bilingual speakers
speech for cross-language voice conversion,” J. Acoust.
Soc. Am., vol. 90, no. 1, pp. 76–82, 1991.
[27] Mikiko Mashimo, Tomoki Toda, Kiyohiro Shikano, and
Nick Campbell, “Evaluation of cross-language voice
conversion based on GMM and Straight,” in Proc. EU-
ROSPEECH, 2001, pp. 361–364.
[28] Yi Zhou, Xiaohai Tian, Haihua Xu, Rohan Kumar Das,
and Haizhou Li, “Cross-lingual voice conversion with
bilingual phonetic posteriorgram and average model-
ing,” in Proc. ICASSP, 2019, pp. 6790–6794.
[29] Sai Sirisha Rallabandi and Suryakanth V Gangashetty,
“An approach to cross-lingual voice conversion,” in
Proc. IJCNN, 2019.
[30] Yi-Jian Wu, Yoshihiko Nankaku, and Keiichi Tokuda,
“State mapping based method for cross-lingual speaker
adaptation in hmm-based speech synthesis,” in Proc.
INTERSPEECH, 2009, pp. 528–531.
[31] Ewan Dunbar, Robin Algayres, Julien Karadayi, Math-
ieu Bernard, Juan Benjumea, Xuan-Nga Cao, Lucie
Miskic, Charlotte Dugrain, Lucas Ondel, Alan W.
Black, Laurent Besacier, Sakriani Sakti, and Emmanuel
Dupoux, “The zero resource speech challenge 2019:
TTS without T,” arXiv preprint arXiv:1904.11469,
2019.
[32] Siyuan Feng, Tan Lee, and Zhiyuan Peng, “Combining
adversarial training and disentangled speech representa-
tion for robust zero-resource subword modeling,” arXiv
preprint arXiv:1906.07234, 2019.
[33] Andy T Liu, Po-chun Hsu, and Hung-yi Lee, “Unsu-
pervised end-to-end learning of discrete linguistic units
for voice conversion,” arXiv preprint arXiv:1905.11563,
2019.
[34] Ryan Eloff, Andr
´
e Nortje, Benjamin van Niekerk,
Avashna Govender, Leanne Nortje, Arnu Pretorius,
Elan Van Biljon, Ewald van der Westhuizen, Lisa
van Staden, and Herman Kamper, “Unsupervised
acoustic unit discovery for speech synthesis using dis-
crete latent-variable neural networks,” arXiv preprint
arXiv:1904.07556, 2019.
[35] Sunayana Sitaram, Sukhada Palkar, Yun-Nung Chen,
Alok Parlikar, and Alan W Black, “Bootstrapping text-
to-speech for speech processing in languages without an
orthography,” in Proc. ICASSP, 2013, pp. 7992–7996.
[36] Prasanna Kumar Muthukumar and Alan W Black, “Au-
tomatic discovery of a phonetic inventory for unwrit-
ten languages for statistical speech synthesis,” in Proc.
ICASSP, 2014, pp. 2594–2598.
[37] Christophe Veaux, Junichi Yamagishi, and Kirsten
MacDonald, “CSTR VCTK corpus: English multi-
speaker corpus for CSTR voice cloning toolkit,” 2017,
http://dx.doi.org/10.7488/ds/1994.
[38] Jaime Lorenzo-Trueba, Junichi Yamagishi, Tomoki
Toda, Daisuke Saito, Fernando Villavicencio, Tomi Kin-
nunen, and Zhenhua Ling, “The voice conversion chal-
lenge 2018: Promoting development of parallel and
nonparallel methods,” in Proc. Odyssey, 2018, pp. 195–
202.
[39] Kazuhiro Kobayashi and Tomoki Toda, “sprocket:
Open-source voice conversion software,” in Proc.
Odyssey, 2018, pp. 203–210.
[40] Li-Juan Liu, Zhen-Hua Ling, Yuan Jiang, Ming Zhou,
and Li-Rong Dai, “Wavenet vocoder with limited train-
ing data for voice conversion,” in Proc. INTERSPEECH,
2018, pp. 1983–1987.
[41] Tao Tu, Yuan-Jui Chen, Cheng-chieh Yeh, and Hung-
yi Lee, “End-to-end text-to-speech for low-resource
languages by cross-lingual transfer learning,” arXiv
preprint arXiv:1904.06508, 2019.
